
Here the authors performed a comparative analysis to investigate the viability of using PLAY® instead of fetal bovine serum (FBS) as a growth medium to culture cells with an enzyme-linked immunosorbent assay.
Read More...An in vitro comparative analysis of the growth factors present in FBS vs PLAY®
Here the authors performed a comparative analysis to investigate the viability of using PLAY® instead of fetal bovine serum (FBS) as a growth medium to culture cells with an enzyme-linked immunosorbent assay.
Read More...Risk factors contributing to Pennsylvania childhood asthma
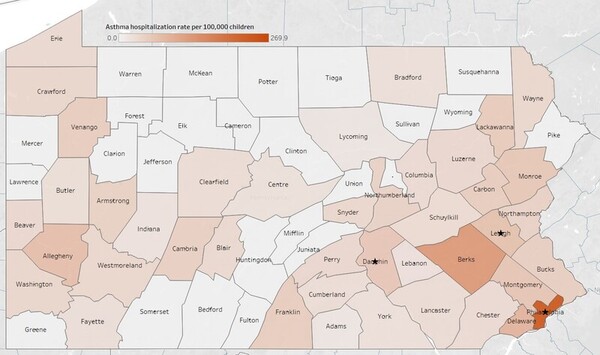
Asthma is one of the most prevalent chronic conditions in the United States. But not all people experience asthma equally, with factors like healthcare access and environmental pollution impacting whether children are likely to be hospitalized for asthma's effects. Li, Li, and Ruffolo investigate what demographic and environmental factors are predictive of childhood asthma hospitalization rates across Pennsylvania.
Read More...Survival analysis in cardiovascular epidemiology: nexus between heart disease and mortality
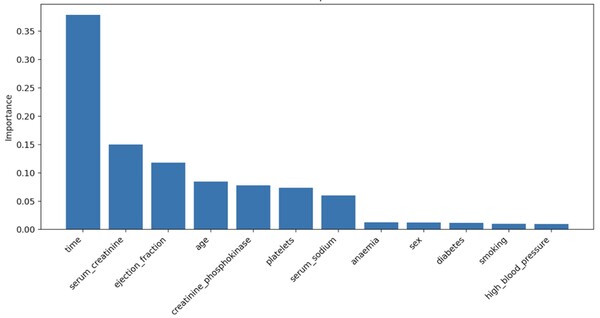
In 2021, over 20 million people died from cardiovascular diseases, highlighting the need for a deeper understanding of factors influencing heart failure outcomes. This study examined multiple variables affecting mortality after heart failure, using random forest models to identify time, serum creatinine, and ejection fraction as key predictors. These findings could contribute to personalized medicine, improving survival rates by tailoring treatment strategies for heart failure patients.
Read More...Stress and depression among individuals with low socioeconomic status during economic inflation
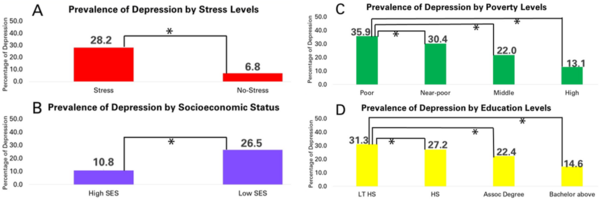
The authors use the Census Household Pulse Survey issued by the US Census Bureau to examine the prevalence of stress and depression among people across socioeconomic statuses.
Read More...Do perceptions of beauty differ based on rates of racism, ethnicity, and ethnic generation?
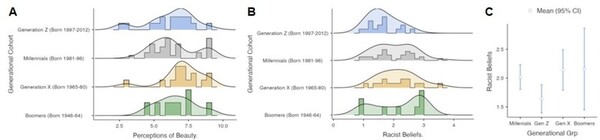
The authors examine the relationships between race, racist beliefs, and perceptions of beauty across cultures and generations.
Read More...Generation of a magnetic field on Mars

The authors propose and test a method that would allow for the generation of a magnetic field on Mars sufficient to support future colonization.
Read More...Investigating momentum transfer with gall-forming wasps
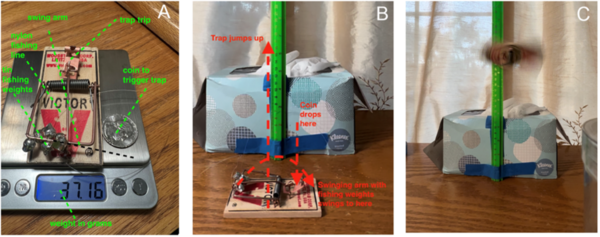
The authors use the unique movements of the jumping gall wasp to study momentum transfer with potential applications in robotics and extraterrestrial research.
Read More...Transfer Learning with Convolutional Neural Network-Based Models for Skin Cancer Classification
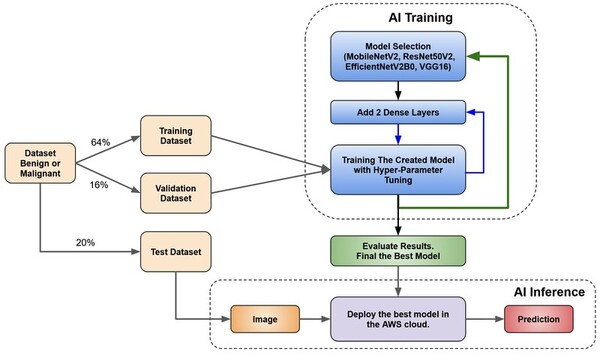
Skin cancer is a common and potentially deadly form of cancer. This study’s purpose was to develop an automated approach for early detection for skin cancer. We hypothesized that convolutional neural network-based models using transfer learning could accurately differentiate between benign and malignant moles using natural images of human skin.
Read More...Testing Simarouba amara’s therapeutic effects against weedicide-induced tumor-like morphology in planarians
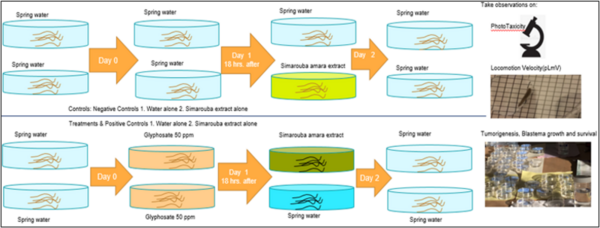
According to the World Health Organization, cancer is a leading cause of death globally. The disease’s prevalence is rapidly increasing in association with factors including the increased use of pesticides and herbicides, such as glyphosate, which is one of the most widely used herbicide ingredients. Natural antioxidants and phytochemicals are being tested as anti-cancer agents due to their antiproliferative, antioxidative, and pro-apoptotic properties. Thus, we aimed to investigate the potential role of S. amara extract as a therapeutic agent against glyphosate-induced toxicity and tumor-like morphologies in regenerating and homeostatic planaria (Dugesia dorotocephala).
Read More...The effects of social media on STEM identity in adolescent girls

Social media is widely used and easily accessible for adolescents, it has the potential to increase STEM (Science, Technology, Engineering, and Math) identity in girls. We aimed to investigate the effects of exposure to counter-stereotypical portrayals of women in STEM on social media on the STEM identity of adolescent girls. The study concluded that social media alone may not be an effective tool to increase STEM identity in girls. Social media can still be used as a complementary tool to support and encourage women in STEM, but it should not be relied upon solely to address the gender disparity in STEM fields.
Read More...