Here the authors test the ability of the bacterium Bacillus subtilis to degrade the polyethylene from plastic waste in various aquatic environments. They determined that degradation can occur among all samples while it was the highest in fresh water and lowest in ocean water.
Here the authors introduce pressing filtration as a novel, efficient, and low-energy method for extracting dietary fiber from cabbage, which successfully retains heat-sensitive nutrients and achieves a high fiber yield. The study demonstrates the scalability and economic viability of this technique for commercial use, highlighting that the resulting high-fiber cabbage powder can be incorporated into familiar foods like hamburger buns and beef patties without compromising taste or sensory quality.
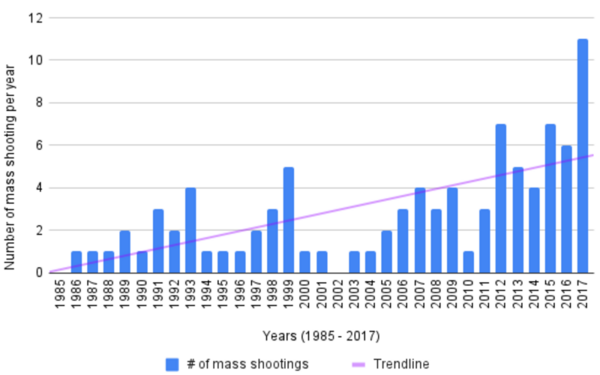
Researching gun violence and mass shootings in the U.S. is difficult due to the lack of consistent data collection. Some studies have linked mass shootings to personal financial stress, but little formal research exists on the impact of broader economic conditions. This study hypothesized an inverse relationship between mass shootings and economic performance, using the S&P 500 and unemployment rate as indicators.
The mountain chain of the Western Ghats on the Indian peninsula, a UNESCO World Heritage site, is home to about 200 frog species, 89 of which are endemic. Distinctive to each frog species, their vocalizations can be used for species recognition. Manually surveying frogs at night during the rain in elephant and big cat forests is difficult, so being able to autonomously record ambient soundscapes and identify species is essential. An effective machine learning (ML) species classifier requires substantial training data from this area. The goal of this study was to assess data augmentation techniques on a dataset of frog vocalizations from this region, which has a minimal number of audio recordings per species. Consequently, enhancing an ML model’s performance with limited data is necessary. We analyzed the effects of four data augmentation techniques (Time Shifting, Noise Injection, Spectral Augmentation, and Test-Time Augmentation) individually and their combined effect on the frog vocalization data and the public environmental sounds dataset (ESC-50). The effect of combined data augmentation techniques improved the model's relative accuracy as the size of the dataset decreased. The combination of all four techniques improved the ML model’s classification accuracy on the frog calls dataset by 94%. This study established a data augmentation approach to maximize the classification accuracy with sparse data of frog call recordings, thereby creating a possibility to build a real-world automated field frog species identifier system. Such a system can significantly help in the conservation of frog species in this vital biodiversity hotspot.
Here, the authors used machine learning to analyze microscopic images of hair, quantifying various features to distinguish individuals, even within families where traditional DNA analysis is limited. The Discriminant Analysis (DA) model achieved the highest accuracy (88.89%) in identifying individuals, demonstrating its potential to improve the reliability of hair evidence in forensic investigations.
Aquaponics (the combination of aquatic plant farming with fish production) is an innovative farming practice, but the fish that are typically used, like tilapia, are expensive and space-consuming to cultivate. Medina and Alvarez explore other options test if mosquitofish are a viable option in the aquaponic cultivation of herbs and microgreens.
This article describes the classification of medical text data using vector databases and text embedding. Various large language models were used to generate this medical data for the classification task.
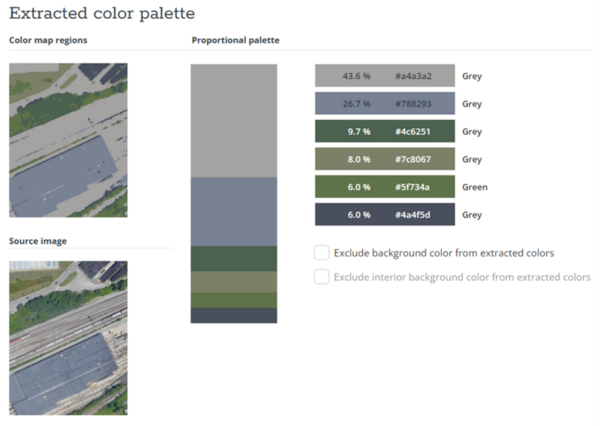
Almost all urban areas face the challenge of urban heat islands, areas with substantially hotter land surface temperatures than the surrounding rural areas. These areas are associated with worse air and water
quality, increased power outages, and increased heat-related illnesses. To learn more about these areas, Ustin et al. analyze satellite images of Cleveland neighborhoods to find out if there is a correlation between surface area development and surface temperature.
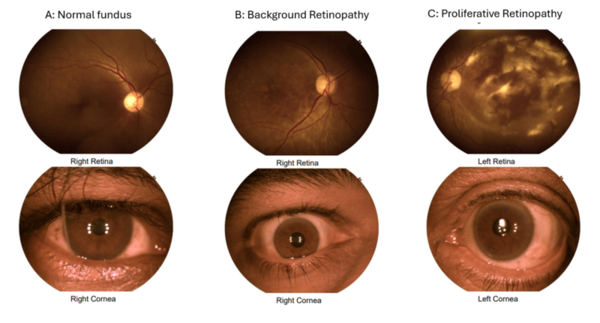
The purpose of our study was to examine the correlation of glycosylated hemoglobin (HbA1c), blood pressure (BP) readings, and lipid levels with retinopathy. Our main hypothesis was that poor glycemic control, as evident by high HbA1c levels, high blood pressure, and abnormal lipid levels, causes an increased risk of retinopathy. We identified the top two features that were most important to the model as age and HbA1c. This indicates that older patients with poor glycemic control are more likely to show presence of retinopathy.