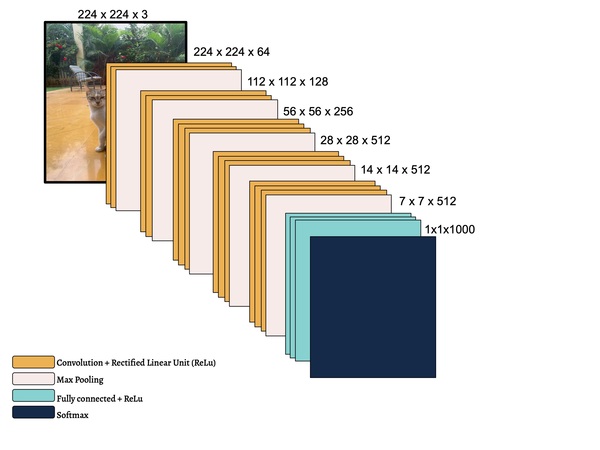
In this study, the authors seek to improve a machine learning algorithm used for image classification: identifying male and female images. In addition to fine-tuning the classification model, they investigate how accuracy is affected by their changes (an important task when developing and updating algorithms). To determine accuracy, a set of images is used to train the model and then a separate set of images is used for validation. They found that the validation accuracy was close to the training accuracy. This study contributes to the expanding areas of machine learning and its applications to image identification.
Read More...