
The authors looked at the importance of different point breakdowns needed to win in a game of tennis.
Read More...Optimizing tennis strategy: a data-driven analysis of point importance
The authors looked at the importance of different point breakdowns needed to win in a game of tennis.
Read More...Epileptic seizure detection using machine learning on electroencephalogram data
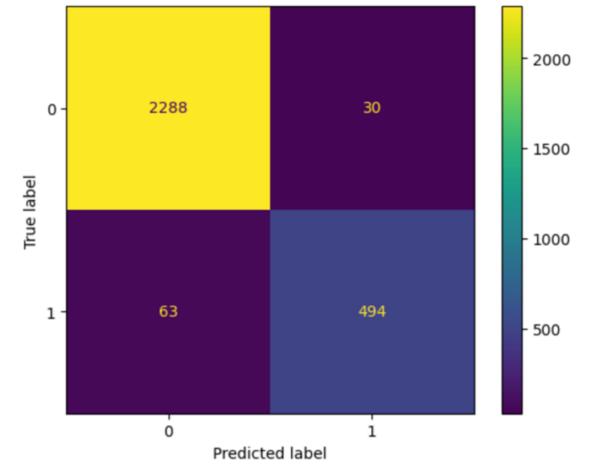
The authors use machine learning and electroencephalogram data to propose a method for improving epilepsy diagnosis.
Read More...Locating sources of a high energy cosmic ray extensive air shower using HiSPARC data

Using the data provided by the University of Twente High School Project on Astrophysics Research with Cosmics (HiSPARC), an analysis of locations for possible high-energy cosmic ray air showers was conducted. An example includes an analysis conducted of the high-energy rain shower recorded in January 2014 and the use of Stellarium™ to discern its location.
Read More...Comparing model-centric and data-centric approaches to determine the efficiency of data-centric AI
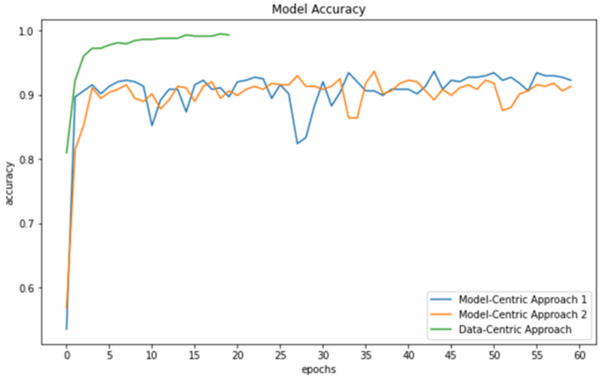
In this study, three models are used to test the hypothesis that data-centric artificial intelligence (AI) will improve the performance of machine learning.
Read More...Early detection of student burnout using data science: a study of behavioral and psychological indicators

This study examined behavioral and psychological predictors of burnout among high school and university students in Pakistan using survey data and machine-learning models. Shorter sleep and greater mental fatigue—especially fatigue—were associated with higher burnout risk, while a Random Forest model successfully identified students at risk of burnout.
Read More...Evaluating the effectiveness of synthetic training data for day-ahead wind speed prediction in the Great Lakes
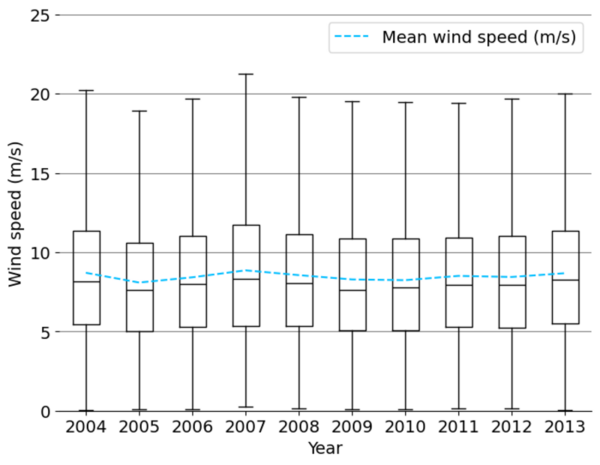
The authors looked at the feasibility to predict wind speeds that will have less reliance on using historical data.
Read More...Training neural networks on text data to model human emotional understanding
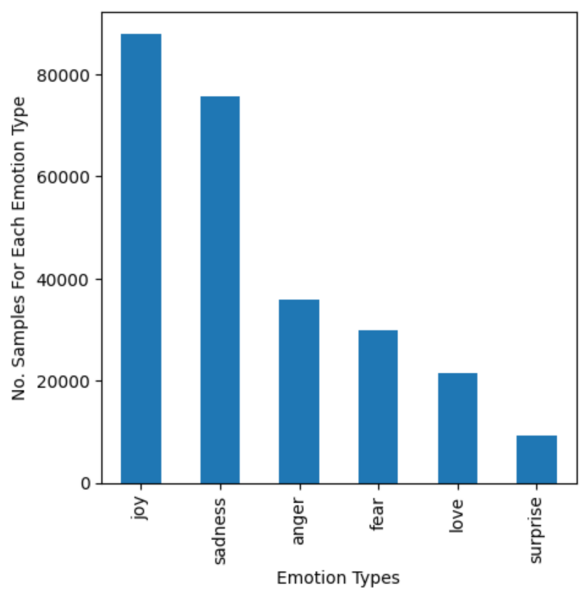
The authors train a neural network to detect text-based emotions including joy, sadness, anger, fear, love, and surprise.
Read More...Uncovering the hidden trafficking trade with geographic data and natural language processing

The authors use machine learning to develop an evidence-based detection tool for identifying human trafficking.
Read More...Effects of different synthetic training data on real test data for semantic segmentation

Semantic segmentation - labelling each pixel in an image to a specific class- models require large amounts of manually labeled and collected data to train.
Read More...Heat conduction: Mathematical modeling and experimental data
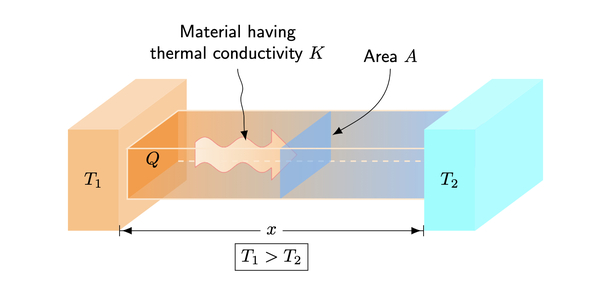
In this experiment, the authors modify the heat equation to account for imperfect insulation during heat transfer and compare it to experimental data to determine which is more accurate.
Read More...